Text-mining a section of a website
Source:vignettes/articles/text-mining-workflow.Rmd
text-mining-workflow.RmdOne of the first issues that appear when starting a text mining or
web scraping project relates to the issue of managing files and folder.
castarter defaults to an opinionated folder structure that
should work for most projects. It also facilitates downloading files
(skipping previously downloaded files) and ensuring consistent and
unique matching between a downloaded html, its source url, and data
extracted from them. Finally, it facilitates archiving and backuping
downloaded files and scripts.
Getting started
In this vignette, I will outline some of the basic steps that can be used to extract and process the contents of press releases from a number of institutions of the European Union. When text mining or scraping, it is common to gather quickly many thousands of file, and keeping them in good order is fundamental, particularly in the long term.
A preliminary suggestion: depending on how you usually work and keep
your files backed-up it may make sense to keep your scripts in a folder
that is live-synced (e.g. with services such as Dropbox, Nextcloud, or
Google Drive). It however rarely make sense to live-sync tens or
hundreds of thousands of files as you proceed with your scraping. You
may want to keep this in mind as you set the base_folder
with cas_set_options(). I will keep in the current working
directory here for the sake of simplicity, but there are no drawbacks in
having scripts and folders in different locations.
castarter stores details about the download process in a
database. By default, this is stored locally in DuckDB database kept in
the same folder as website files, but it can be stored in a different
folder, or alternative database backends such as RSQlite or MySQL can
also be used.
Assuming that my project on the European Union involves text mining the website of the European Parliament, the European Council, and the External action service (EEAS) the folder structure may look something like this:
library("castarter")
cas_set_options(
base_folder = fs::path_home(
"R",
"castarter_data"
),
project = "European Union",
website = "European Parliament"
)#> ../../../../../R/castarter_data
#> ├── European Union
#> │ ├── EEAS
#> │ ├── European Committee of Regions
#> │ ├── European Council
#> │ └── European Parliament
#> ├── European journalism
#> │ └── EDJNet
#> └── Space
#> └── Italian Space AgencyIn brief, castarter_data is the base folder where I can
store all of my text mining projects. European Union is the
name of the project, while all others are the names of the specific
websites I will source. The user will be prompted to accept creating
folder as needed when starting to download the files.
Downloading index files
In text mining a common scenario involves first downloading web pages containing lists of urls to the actual posts we are interested in. In the case of the European Commission, these would probably be the pages in the “news section”. By clicking on the the numbers at the bottom of the page, we get to see direct links to the subsequent pages listing all posts.
These URLs look something like this:
#> # A tibble: 10 × 1
#> index_urls
#> <chr>
#> 1 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=1
#> 2 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=2
#> 3 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=3
#> 4 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=4
#> 5 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=5
#> 6 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=6
#> 7 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=7
#> 8 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=8
#> 9 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=9
#> 10 https://ec.europa.eu/commission/presscorner/home/en?pagenumber=10Sometimes such urls can be derived from the archive section, as is the case for example for EEAS:
index_df <- cas_build_urls(
url = "https://www.eeas.europa.eu/eeas/press-material_en?f%5B0%5D=pm_category%253AStatement/Declaration&f%5B1%5D=press_site%253AEEAS&f%5B2%5D=press_site%253AEEAS&fulltext=&created_from=&created_to=&0=press_site%253AEEAS&1=press_site%253AEEAS&2=press_site%253AEEAS&page=",
start_page = 0,
end_page = 3,
index_group = "Statements"
)
index_df
#> # A tibble: 4 × 3
#> id url index_group
#> <dbl> <chr> <chr>
#> 1 1 https://www.eeas.europa.eu/eeas/press-material_en?f%5B0%5D=… Statements
#> 2 2 https://www.eeas.europa.eu/eeas/press-material_en?f%5B0%5D=… Statements
#> 3 3 https://www.eeas.europa.eu/eeas/press-material_en?f%5B0%5D=… Statements
#> 4 4 https://www.eeas.europa.eu/eeas/press-material_en?f%5B0%5D=… StatementsAll information about index urls and the download process are typically stored in a local database for consistency and future reference.
A practical example: retrieving posts published on the website of the EU Parliament
Each of the following steps is documented in more details considering alternative scenarios in the dedicated vignettes. In the following walkthrough we’ll proceed with a basic scenario, simply retrieving the latest posts published on the European Parliament website.
First, let’s define the directory where all files and information will be stored.
library("castarter")
cas_set_options(
base_folder = fs::path_home(
"R",
"castarter_data"
),
project = "European Union",
website = "European Parliament"
)We create the urls of the index pages:
index_df <- cas_build_urls(
url = "https://www.europarl.europa.eu/news/en/page/",
start_page = 1,
end_page = 10, # 600,
index_group = "news"
)
index_df
#> # A tibble: 10 × 3
#> id url index_group
#> <dbl> <chr> <chr>
#> 1 1 https://www.europarl.europa.eu/news/en/page/1 news
#> 2 2 https://www.europarl.europa.eu/news/en/page/2 news
#> 3 3 https://www.europarl.europa.eu/news/en/page/3 news
#> 4 4 https://www.europarl.europa.eu/news/en/page/4 news
#> 5 5 https://www.europarl.europa.eu/news/en/page/5 news
#> 6 6 https://www.europarl.europa.eu/news/en/page/6 news
#> 7 7 https://www.europarl.europa.eu/news/en/page/7 news
#> 8 8 https://www.europarl.europa.eu/news/en/page/8 news
#> 9 9 https://www.europarl.europa.eu/news/en/page/9 news
#> 10 10 https://www.europarl.europa.eu/news/en/page/10 newsStore them in the local database:
cas_write_db_index(urls = index_df)
#> ℹ Folder /tmp/RtmprKtXJ9/R/castarter_data for storing project and website files
#> created.
#> ✔ Urls added to index_id table: 10
cas_read_db_index()
#> # Source: table<`index_id`> [?? x 3]
#> # Database: sqlite 3.51.2 [/tmp/RtmprKtXJ9/R/castarter_data/cas_European Union_European Parliament_db.sqlite]
#> id url index_group
#> <dbl> <chr> <chr>
#> 1 1 https://www.europarl.europa.eu/news/en/page/1 news
#> 2 2 https://www.europarl.europa.eu/news/en/page/2 news
#> 3 3 https://www.europarl.europa.eu/news/en/page/3 news
#> 4 4 https://www.europarl.europa.eu/news/en/page/4 news
#> 5 5 https://www.europarl.europa.eu/news/en/page/5 news
#> 6 6 https://www.europarl.europa.eu/news/en/page/6 news
#> 7 7 https://www.europarl.europa.eu/news/en/page/7 news
#> 8 8 https://www.europarl.europa.eu/news/en/page/8 news
#> 9 9 https://www.europarl.europa.eu/news/en/page/9 news
#> 10 10 https://www.europarl.europa.eu/news/en/page/10 newsDownload index files
And then start downloading the index files:
cas_download_index(create_folder_if_missing = TRUE)Check how the download is going
download_status_df <- cas_read_db_download(index = TRUE)
download_status_df
#> # A tibble: 0 × 5
#> # ℹ 5 variables: id <dbl>, batch <dbl>, datetime <dttm>, status <int>,
#> # size <fs::bytes>Extract links from index files
Time to extract links from the index page. In this case, we’ll keep
things simple, and take any link that includes in the url the following
string news/en/press-room/. We first test this approach
without storing it in the local database (setting
write_to_db to FALSE), and then, if it works, we move
ahead.
links_df <- cas_extract_links(
include_when = "news/en/press-room/",
write_to_db = FALSE
)It’s usually a good idea to give a quick look at results and then check if a consistent number of links has been extracted from each index page.
links_df |>
head()
#> # A tibble: 0 × 5
#> # ℹ 5 variables: id <dbl>, url <chr>, link_text <chr>, source_index_id <dbl>,
#> # source_index_batch <dbl>You will notice that this table includes information about where each link has been found, i.e., the id of the relevant index page. This allows us to always be able to answer the question “where did I find this link?”: the source page, and the time when it was downloaded, are all stored in the local database by default.
We can also see that from each index page we retrieved 15 unique links, also a good indicator that things are as expected.
links_df |>
dplyr::group_by(source_index_id) |>
dplyr::tally() |>
dplyr::collect()
#> # A tibble: 0 × 2
#> # ℹ 2 variables: source_index_id <dbl>, n <int>We can proceed with storing the links to the contents pages in the local database. Notice that even if run this command (or the script as a whole) multiple times, there are no negative side effects: by defaults, only pages that are not available locally will be downloaded, and only new index pages will be processed.
cas_extract_links(
include_when = "news/en/press-room/",
write_to_db = TRUE
)Time to download.
cas_download(create_folder_if_missing = TRUE)
#> Warning: No `contents` urls for download stored in database.
#> No new files or pages to download.Keeping in mind that information about the time of download is stored locally for reference:
cas_read_db_download() |>
head()
#> # A tibble: 0 × 5
#> # ℹ 5 variables: id <dbl>, batch <dbl>, datetime <dttm>, status <int>,
#> # size <fs::bytes>Extracting contents
Now that we have 0 html files stored locally, it’s finally time to extract the information we need, such as title and text.
To do so, we create a list defining how each piece of information should be extracted.
First, we need to open one of the content pages. As they are expected to have all the same structure, we can open one in our browser with:
A typical workflow for finding the right combinations may look as follows: first test what works on a single page or a small set of pages, and then let the extractor process all pages.
The specifics of extracting fields will be presented separately, but folks familiar with the way html pages are built will understand the gist of it just by looking at a few examples below. What is worth highlighting is that by relying on the source code of the page often it is possible to access information in a structured form that is not normally visible to the user, including keywords passed to search engines and a description field commonly used by social media for the preview of the page.
In this case, this allows for example to extract whether a given post is associated with a EU Parliament committee.
This approach allows for extracting how many fields as needed, accepting that some of them may be empty for some pages (for example, some of the post on EP website have a factbox, others don’t).
extractors_l <- list(
title = \(x) cas_extract_html(
html_document = x,
container = "h1",
container_class = "ep_title"
),
date = \(x) cas_extract_html(
html_document = x,
container = "time",
container_itemprop = "datePublished",
attribute = "datetime",
container_instance = 1
) |>
lubridate::ymd_hms() |>
lubridate::as_date(),
datetime = \(x) cas_extract_html(
html_document = x,
container = "time",
container_itemprop = "datePublished",
attribute = "datetime",
container_instance = 1
) |>
lubridate::ymd_hms(),
description = \(x) cas_extract_html(html_document = x,
container = "meta",
container_property = "og:description",
attribute = "content"),
type = \(x) cas_extract_html(html_document = x,
container = "meta",
container_name = "keywords",
attribute = "content") |>
stringr::str_extract("productType:[[:print:]]+") |>
stringr::str_remove("productType:") |>
stringr::str_extract("[[:print:]]+,") |>
stringr::str_remove(","),
subtype = \(x) cas_extract_html(html_document = x,
container = "meta",
container_name = "routes",
attribute = "content") |>
stringr::str_extract("productSubType:[[:print:]]+") |>
stringr::str_remove("productSubType:"),
committee = \(x) cas_extract_html(html_document = x,
container = "meta",
container_name = "keywords",
attribute = "content") |>
stringr::str_extract("com:[[:print:]]+") |>
stringr::str_remove("com:") |>
stringr::str_extract("[[:print:]]+,") |>
stringr::str_replace_all(pattern = "com:", replacement = "; ") |>
stringr::str_remove_all(","),
facts = \(x) cas_extract_html(
html_document = x,
container = "div",
container_class = "ep-a_facts"
),
text = \(x) cas_extract_html(
html_document = x,
container = "div",
container_class = "ep_gridcolumn-content",
sub_element = "p"
)
)
set.seed(10)
current_file <- cas_get_path_to_files(sample = 1)
# current_file <- cas_get_path_to_files(id = 1)
# x <- xml2::read_html(current_file$path)
# cas_browse(id = current_file$id)
test_df <- cas_extract(extractors = extractors_l,
id = current_file$id,
write_to_db = FALSE,
check_previous = FALSE)
if (is.null(test_df)==FALSE) {
test_df |>
dplyr::collect() |>
dplyr::mutate(text = stringr::str_trunc(string = text, width = 160)) |>
tidyr::pivot_longer(cols = dplyr::everything()) |>
knitr::kable()
}
cas_extract(extractors = extractors_l,
write_to_db = FALSE)Output
corpus_df <- cas_read_db_contents_data()All at once
All of the above can be achieved with the following script:
library("castarter")
cas_set_options(
base_folder = fs::path_home(
"R",
"castarter_eu"
),
project = "European Union",
website = "European Parliament"
)
cas_build_urls(
url = "https://www.europarl.europa.eu/news/en/page/",
start_page = 1,
end_page = 600,
index_group = "news",
write_to_db = TRUE
)
#> ✔ Urls added to index_id table: 590
#> # A tibble: 600 × 3
#> id url index_group
#> <dbl> <chr> <chr>
#> 1 1 https://www.europarl.europa.eu/news/en/page/1 news
#> 2 2 https://www.europarl.europa.eu/news/en/page/2 news
#> 3 3 https://www.europarl.europa.eu/news/en/page/3 news
#> 4 4 https://www.europarl.europa.eu/news/en/page/4 news
#> 5 5 https://www.europarl.europa.eu/news/en/page/5 news
#> 6 6 https://www.europarl.europa.eu/news/en/page/6 news
#> 7 7 https://www.europarl.europa.eu/news/en/page/7 news
#> 8 8 https://www.europarl.europa.eu/news/en/page/8 news
#> 9 9 https://www.europarl.europa.eu/news/en/page/9 news
#> 10 10 https://www.europarl.europa.eu/news/en/page/10 news
#> # ℹ 590 more rows
cas_download_index()
cas_extract_links(
include_when = "news/en/press-room/",
write_to_db = TRUE
)
cas_download()
#> Warning: No `contents` urls for download stored in database.
#> No new files or pages to download.
cas_extract(extractors = extractors_l,
write_to_db = TRUE)Extracted contents are stored in a local database and can be retrieved with:
corpus_df <- cas_read_db_contents_data() |>
dplyr::collect()
str(corpus_df)
#> tibble [7,700 × 11] (S3: tbl_df/tbl/data.frame)
#> $ id : chr [1:7700] "1" "2" "3" "4" ...
#> $ url : chr [1:7700] "https://www.europarl.europa.eu/news/en/press-room/20250310IPR27226/european-parliament-to-establish-western-bal"| __truncated__ "https://www.europarl.europa.eu/news/en/press-room/20250310IPR27224/european-parliament-to-establish-eastern-par"| __truncated__ "https://www.europarl.europa.eu/news/en/press-room/20250307IPR27191/ep-today" "https://www.europarl.europa.eu/news/en/press-room/20250310IPR27217/european-parliament-to-mark-international-women-s-day" ...
#> $ title : chr [1:7700] "European Parliament to establish Western Balkans office in Albania" "European Parliament to establish Eastern Partnership office in Moldova" "EP TODAY" "European Parliament to mark International Women’s Day" ...
#> $ date : chr [1:7700] "2025-03-10" "2025-03-10" "2025-03-10" "2025-03-10" ...
#> $ datetime : chr [1:7700] "2025-03-10 19:21:00" "2025-03-10 19:21:00" "2025-03-10 14:20:00" "2025-03-10 11:57:00" ...
#> $ description: chr [1:7700] "The European Parliament will open an office in Albania to further strengthen its engagement with the Western Balkans." "The European Parliament will open an office in Moldova to further strengthen Parliament’s engagement with the E"| __truncated__ "Monday, 10 March" "On Tuesday at noon, MEPs will celebrate International Women’s Day (8 March) at a special event in the Strasbourg hemicycle." ...
#> $ type : chr [1:7700] NA NA "PRESS_RELEASE" NA ...
#> $ subtype : chr [1:7700] "GENERAL" "GENERAL" "PLENARY_SESSION" "GENERAL" ...
#> $ committee : chr [1:7700] NA NA NA NA ...
#> $ facts : chr [1:7700] "" "" "" "" ...
#> $ text : chr [1:7700] "The European Parliament will open an office in Albania to further strengthen its engagement with the Western Ba"| __truncated__ "The European Parliament will open an office in Moldova to further strengthen Parliament’s engagement with the E"| __truncated__ "Monday, 10 March\nLast-minute press briefing at 16.30\nThe Parliament’s Spokesperson and the Press Service will"| __truncated__ "On Tuesday at noon, MEPs will celebrate International Women’s Day (8 March) at a special event in the Strasbour"| __truncated__ ...Time to process results
The easiest way to explore results is probably by using the
interactive web interface provided by castarter, which
facilitates basic word frequency operations and exporting subset based
on pattern matching:
Consider that you may have some efficiency gains (in terms of speed
and memory demands) by reading the corpus from a local
arrow file. Write it with
cas_write_corpus(partition = "year"), and pass it to
cas_explorer() with
cas_read_corpus(partition = "year")
You can also explore the corpus with some of the convenience functions provided by the package. Here are a couple of examples.
Total word count per year:
cas_count_total_words(corpus = corpus_df |>
dplyr::mutate(year = lubridate::year(date)),
group_by = year) |>
knitr::kable()| year | n |
|---|---|
| 2009 | 394 |
| 2010 | 137834 |
| 2011 | 294537 |
| 2012 | 254812 |
| 2013 | 220850 |
| 2014 | 176055 |
| 2015 | 185288 |
| 2016 | 194326 |
| 2017 | 178329 |
| 2018 | 194732 |
| 2019 | 154947 |
| 2020 | 209874 |
| 2021 | 242861 |
| 2022 | 270198 |
| 2023 | 260331 |
| 2024 | 215560 |
| 2025 | 25994 |
Basic graph with number of mentions of “crisis” per year:
cas_count(
corpus = corpus_df,
pattern = c("crisis")
) |>
cas_summarise(period = "year") |>
cas_show_gg_base() |>
cas_show_barchart_ggplot2(position = "stack")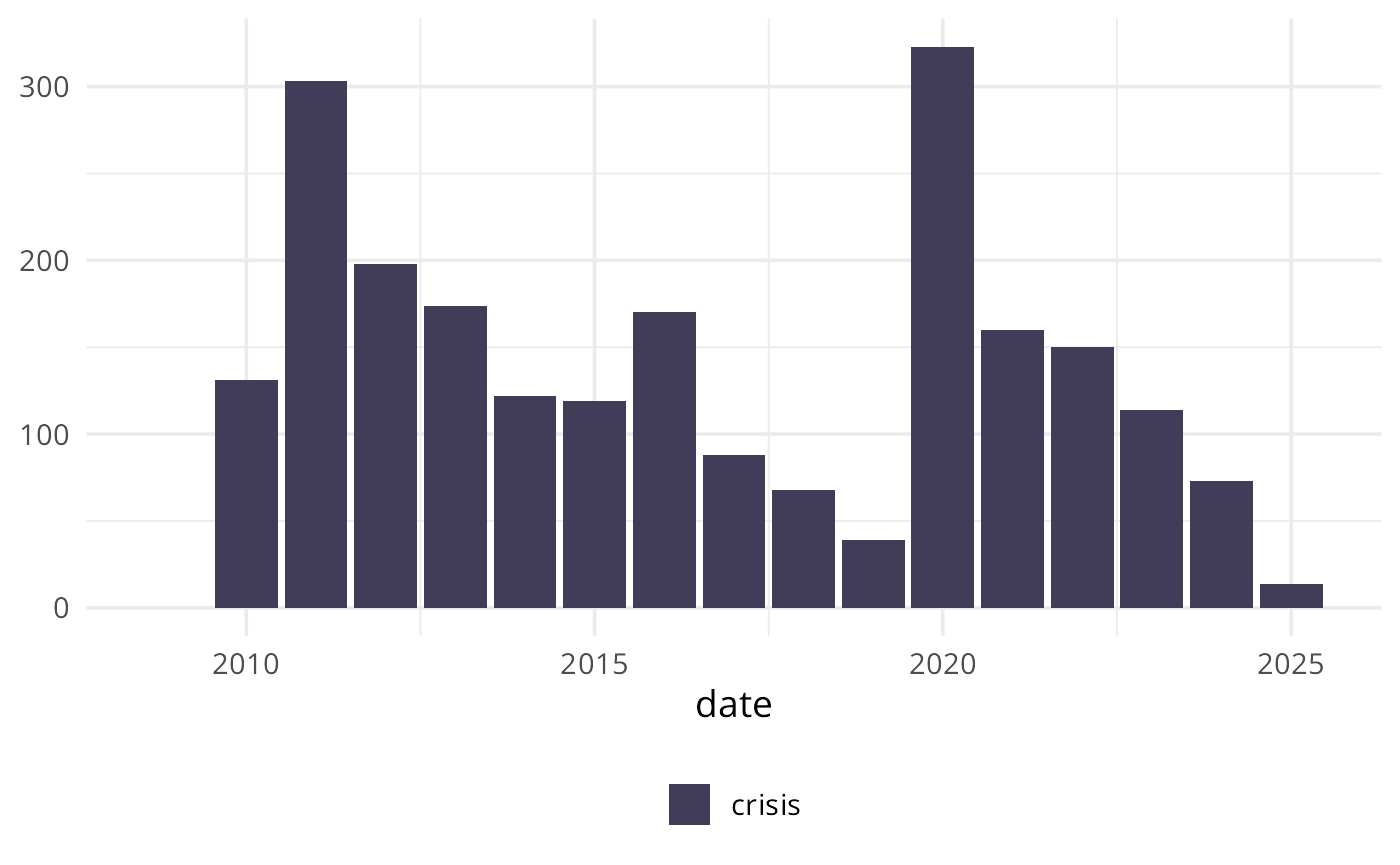
The keyword “crisis” in context:
cas_kwic(corpus = corpus_df |> head(100),
pattern = "crisis") |>
dplyr::select(before, pattern, after)
#> # A tibble: 24 × 3
#> before pattern after
#> <chr> <chr> <chr>
#> 1 Commissioner for Equality, Preparedness, and Crisis Management.
#> 2 spaceimaging and AI algorithms for crisis management, and improve…
#> 3 with the Parliament on the Crisis Management and Deposit …
#> 4 territorial cohesion funding only for crisis support or other time-s…
#> 5 appropriate measures to address the crisis and pressure Rwanda to …
#> 6 for humanitarian access to the crisis area and breaks all lin…
#> 7 into a political and constitutional crisis the country has witness…
#> 8 only solution to the current crisis in Georgia is holding n…
#> 9 assess the conflict and humanitarian crisis in the Democratic Repub…
#> 10 contribute to resolving the humanitarian crisis of people missing in wa…
#> # ℹ 14 more rowsWe should also keep in mind that by extracting more information, besides the text, we may use them to filter contents or to derive additional information, e.g. which committees have been tagged in most posts:
corpus_df |>
dplyr::filter(is.na(committee)==FALSE) |>
dplyr::mutate(committee = stringr::str_split(string = committee, pattern = "; ")) |>
dplyr::select(id, committee) |>
tidyr::unnest(committee) |>
dplyr::count(committee, sort = TRUE)
#> # A tibble: 39 × 2
#> committee n
#> <chr> <int>
#> 1 AFET 381
#> 2 ENVI 256
#> 3 LIBE 233
#> 4 BUDG 210
#> 5 ECON 208
#> 6 ITRE 118
#> 7 IMCO 111
#> 8 FEMM 101
#> 9 INTA 99
#> 10 EMPL 98
#> # ℹ 29 more rowsA simplified workflow: finding links through sitemaps, exracting
contents with readability
The workflow described in the previous steps is highly customisable, but requires some understanding of how html and websites work.
Below, a largely adaptable approach is briefly outlined:
- instead of parsing index pages, of specific sections, links are extracted from the sitemap of the website (assuming that the relevant section from where contents should be extracted can be identified based on part of the url)
- metadata and contents are extracted automatically relying on the
castarter.readabilityplugin, itself based on Mozilla’sreadability.js
N.B. the readability plugin needs to be installed separately
pak::pak("giocomai/castarter.readability")Here is a quick example based on the website of the Italian Space
Agency. castarter finds the sitemap based on the domain
url, and, in order to keep only news posted in English in 2025 it
filters links only when “en/2025” is part of the url.
readability automatically finds title, byline, date
published, and full text of the article.
library("castarter")
cas_set_options(
base_folder = fs::path_home(
"R",
"castarter_data"
),
project = "Space",
website = "Italian Space Agency"
)
sitemap_df <- cas_get_sitemap(domain = "https://www.asi.it/")
cas_build_urls(url = sitemap_df$sitemap_url,
index_group = "base_sitemap",
write_to_db = TRUE)
cas_download_index(file_format = "xml")
cas_extract_links(
index = TRUE,
file_format = "xml",
custom_css = "loc",
index_group = "base_sitemap",
output_index = TRUE,
output_index_group = "sitemap",
write_to_db = TRUE
)
cas_download_index(file_format = "xml")
cas_extract_links(
file_format = "xml",
custom_css = "loc",
index_group = "sitemap", # exclude the base sitemap
include_when = "en/2025", # keep only urls with this string
write_to_db = TRUE
)
download_df <- cas_get_files_to_download()
cas_download(download_df = download_df)
extracted_readability_df <- cas_extract(
extractors = NULL,
readability = TRUE,
write_to_db = FALSE,
check_previous = FALSE
) |>
dplyr::collect()
extracted_readability_df |>
dplyr::slice(1) |>
dplyr::mutate(text = stringr::str_trunc(string = text, width = 140)) |>
tidyr::pivot_longer(cols = dplyr::everything(), values_to = "extracted", names_to = "type") |>
knitr::kable()