How to process datasets efficiently and limiting memory use
Source:vignettes/memory-efficient-reading-of-datasets.Rmd
memory-efficient-reading-of-datasets.RmdGet the dataset
First, let’s take a dataset to use as an example.
library("piggyback")
dataset_path <- fs::path(fs::path_temp(), "castarter_dataset")
fs::dir_create(dataset_path)
piggyback::pb_download(
file = "kremlin.ru_en.csv.gz",
dest = dataset_path,
repo = "giocomai/tadadit",
tag = "kremlin.ru_en",
overwrite = FALSE
)Create dataset variations
As a single parquet file:
dataset_parquet_path <- fs::path(fs::path_temp(), "castarter_dataset_parquet")
fs::dir_create(path = dataset_parquet_path)
original_df %>%
arrow::write_dataset(path = fs::path(dataset_parquet_path))As a parquet file divided partitioned by year.
dataset_parquet_year_path <- fs::path(fs::path_temp(), "castarter_dataset_year_parquet")
fs::dir_create(path = dataset_parquet_year_path)
original_df %>%
dplyr::group_by(year) %>%
arrow::write_dataset(path = dataset_parquet_year_path)Benchmark with detect
ds_py <- arrow::open_dataset(sources = dataset_parquet_year_path)
count <- function(input) {
input %>%
dplyr::filter(stringr::str_detect(
string = text,
pattern = stringr::regex(
pattern = "Ukrain",
ignore_case = TRUE
)
)) %>%
dplyr::mutate(
n = stringr::str_count(
string = text,
pattern = "Ukrain"
)
) %>%
dplyr::group_by(date) %>%
dplyr::summarise(
n = sum(n, na.rm = TRUE),
.groups = "drop"
) %>%
dplyr::arrange(dplyr::desc(date)) %>%
dplyr::collect()
}
results <- bench::mark(
dataset_in_memory = original_df %>% count(),
parquet_single = arrow::open_dataset(sources = dataset_parquet_path) %>% count(),
parquet_by_year = arrow::open_dataset(sources = dataset_parquet_year_path) %>% count(), min_iterations = 10
)
results
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 dataset_in_memory 440ms 447ms 2.23 2.42MB 0
#> 2 parquet_single 393ms 479ms 2.06 10.13MB 0.515
#> 3 parquet_by_year 150ms 156ms 6.19 250.09KB 2.65
summary(object = results, relative = TRUE)
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 dataset_in_memory 2.92 2.87 1.08 9.93 NaN
#> 2 parquet_single 2.61 3.08 1 41.5 Inf
#> 3 parquet_by_year 1 1 3.00 1 Inf
plot(results) +
ggplot2::scale_y_continuous(limits = c(0, NA)) +
ggplot2::labs(title = "str_detect, str_count, group_by, sum")
#> Loading required namespace: tidyr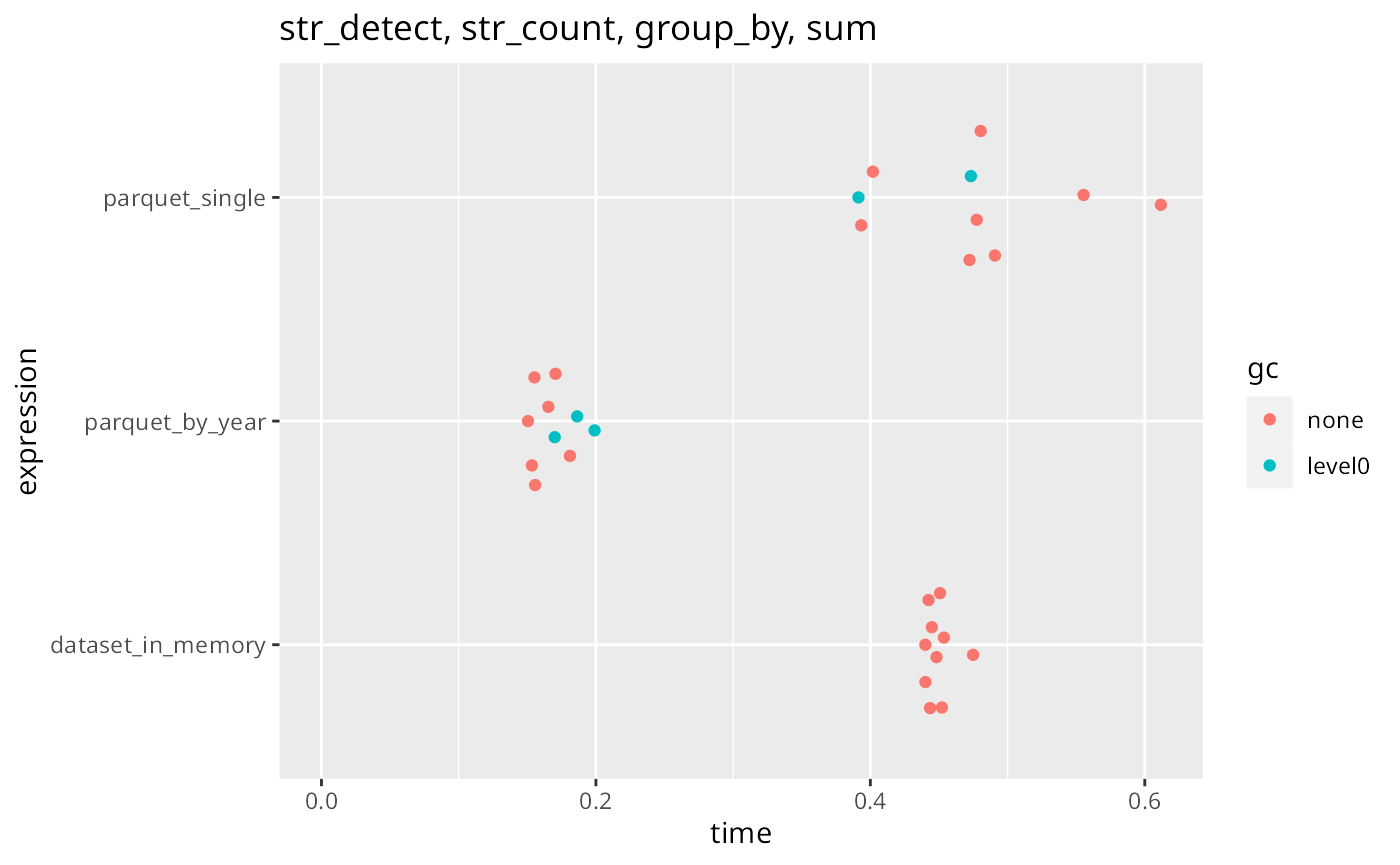
ggplot2::ggsave("arrow.png")
#> Saving 7.29 x 4.51 in imageConclusions
Processing parquet files is more efficient than processing the whole file from memory (even not considering the much smaller memory footprint). Processing the dataset from a parquet file partitioned by year is much faster.
Relying on castarters own internal functions
library("castarter")
cas_set_options(
base_folder = fs::path(
fs::path_home_r(),
"R",
"castarter_tadadit"
),
project = "Russian institutions",
website = "kremlin.ru_ru"
)
count <- function(corpus = cas_read_dataset(),
pattern = "Ukrain") {
corpus %>%
dplyr::filter(stringr::str_detect(
string = text,
pattern = stringr::regex(pattern = pattern, ignore_case = TRUE)
)) %>%
dplyr::mutate(n = stringr::str_count(
string = text,
pattern = pattern
))
# dplyr::summarise({{ n_column_name }} := sum({{ n_column_name }}, na.rm = TRUE),
# .by = {{ group_by }}
# )
}
corpus <- cas_read_corpus()
cas_count(corpus = corpus, pattern = "ukrain")
#> # A tibble: 7,867 × 3
#> date pattern n
#> <chr> <chr> <int>
#> 1 2008-09-26 ukrain 0
#> 2 2008-09-25 ukrain 0
#> 3 2008-09-24 ukrain 0
#> 4 2008-10-01 ukrain 0
#> 5 2008-09-30 ukrain 0
#> 6 2008-09-29 ukrain 0
#> 7 2008-09-28 ukrain 0
#> 8 2008-10-03 ukrain 0
#> 9 2008-10-02 ukrain 0
#> 10 2008-10-07 ukrain 0
#> # ℹ 7,857 more rows
test_count <- function(text_column, n_column_name, patter = "Ukrain") {
cas_read_corpus() %>%
dplyr::mutate({{ n_column_name }} := stringr::str_count(
string = {{ text_column }},
pattern = !!patter
))
}
test_count(text_column = text, n_column_name = n) %>%
dplyr::collect()
#> # A tibble: 51,797 × 14
#> doc_id text id url title date time datetime location description
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 kremlin.ru… Дмит… 1 http… Указ… 2008… 11:00 2008-06… NA ""
#> 2 kremlin.ru… През… 2 http… Указ… 2008… 10:50 2008-06… NA ""
#> 3 kremlin.ru… През… 3 http… Указ… 2008… 19:00 2008-06… NA ""
#> 4 kremlin.ru… Ю.Ба… 4 http… Указ… 2008… 18:45 2008-06… NA ""
#> 5 kremlin.ru… През… 5 http… Указ… 2008… 15:30 2008-05… NA ""
#> 6 kremlin.ru… Возг… 6 http… Утве… 2008… 16:15 2008-05… NA "Дмитрий М…
#> 7 kremlin.ru… Госу… 7 http… Объя… 2008… 12:00 2008-05… Москва,… "По традиц…
#> 8 kremlin.ru… В св… 8 http… Сове… 2008… 13:30 2008-05… Москва,… "Борьбу с …
#> 9 kremlin.ru… В Ро… 9 http… Наци… 2008… 11:00 2008-07… NA ""
#> 10 kremlin.ru… Указ… 10 http… Указ… 2008… 17:30 2008-07… NA ""
#> # ℹ 51,787 more rows
#> # ℹ 4 more variables: keywords <chr>, tags <chr>, tags_links <chr>, n <int>Storing tokenised dataset as parquet
library("castarter")
cas_set_options(
base_folder = fs::path(
fs::path_home_r(),
"R",
"castarter_tadadit"
),
project = "Russian institutions",
website = "kremlin.ru_ru"
)
cas_write_corpus(token = "sentences", partition = "year")